
Accelerate Analytics Value Capture with WANdisco + Databricks
By Paul Scott-Murphy
May 24, 2021
Why just migrate data when you can also modernize your data environment in a way that captures more value from analytics investments, sooner?
Increasingly, organizations that are moving big data to the cloud are committing to innovative platforms like Databricks to replace the majority of what they have implemented on-premises using Hadoop, Spark, and other technologies. By providing a simple, open, and collaborative data ecosystem, Databricks is a compelling and modern platform for data engineering, collaboration, aMake Apache Hive metadatanalytics, and production machine learning.
Yet unlike the relatively clear process of building cloud-native applications from scratch, organizations that want to move from their existing Hadoop deployments to platforms like Databricks in the cloud are faced with significant challenges. The sheer scale of data, the increasingly business-critical nature of big data environments and the complexity that comes with having large numbers of users, or applications, or data sources, all combine to make migrating large data and compute workloads a difficult task.
When you modernize in this way then you can capture more value from analytics investments, sooner.
WANdisco’s unique LiveData approach to migrating data at scale without disrupting the use of those datasets while an organization adopts cloud infrastructure and services has been a critically important answer to these challenges.
From migration to modernization
When your migration goal includes platform modernization, you benefit from having your data immediately available in the cloud (the benefit of Live migration), but you can also benefit from having your data in the cloud in the form that is most appropriate for consumption in your target cloud services.
Cloud-native analytic and machine learning environments like Databricks hold large potential value for organizations that have been constrained by their on-premises infrastructure. It is not just a case of migrating them in a “lift and shift” manner, but of identifying and taking advantage of the opportunities for modernizing those environments at the same time. When you modernize in this way then you can wring more value from analytics investments, sooner.
WANdisco makes data modernization and migration with Databricks easy
WANdisco is launching new capabilities for LiveData Migrator that provide two key Databricks-specific functionalities:
-
Make Apache Hive metadata available directly in Databricks workspaces using Live migration so that ongoing changes to source metadata are reflected immediately in the Databricks target.
-
Transform the on-premises data formats used in Hadoop and Hive to the Databricks-preferred Delta Lake form so that users can take full advantage of the features that are unique to the combination of Databricks and Delta Lake.
By combining data and metadata, and by making on-premises content immediately usable in an ideal form in Databricks, migration tasks that previously required constructing data pipelines to transform, filter and adjust data, as well as significant up-front planning for staging and processing work are now eliminated. Equally, work that would otherwise be required for setting up auto-load pipelines to attempt to identify newly-landed data and convert it to a final form as part of a processing pipeline can be set aside.
Making Hive data and metadata available for direct use as Delta Lake content in Databricks with LiveData Migrator is a simple three-step process.
LiveData Migrator is in control of when datasets land in the cloud so it can initiate the work required to load them into a final form, bypassing the need to detect newly-created data, or identify changes to existing data. It is more efficient, more scalable, and entirely automated.
A simple three step process
Making Hive data and metadata available for direct use as Delta Lake content in Databricks with LiveData Migrator is a simple three-step process:
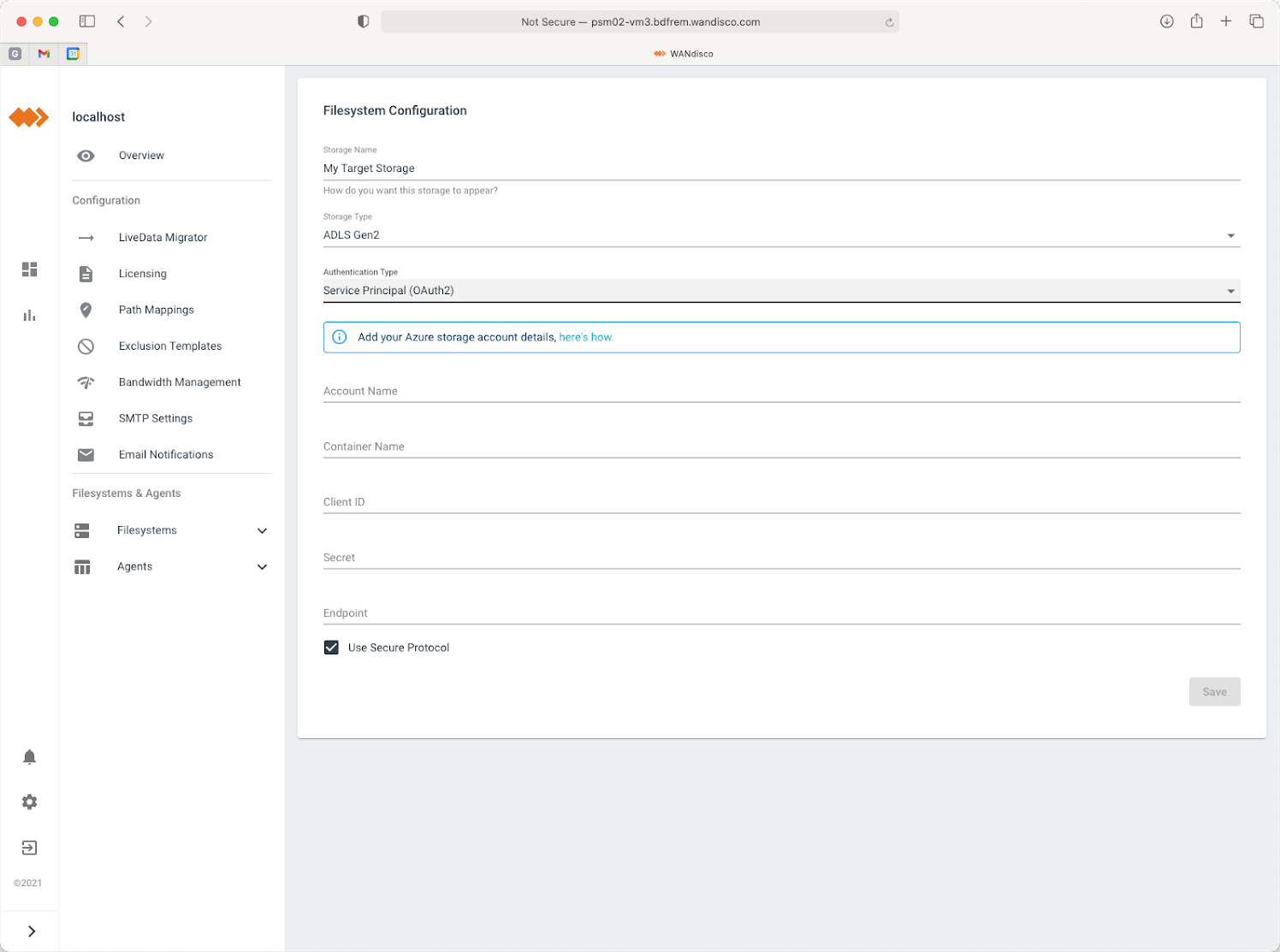
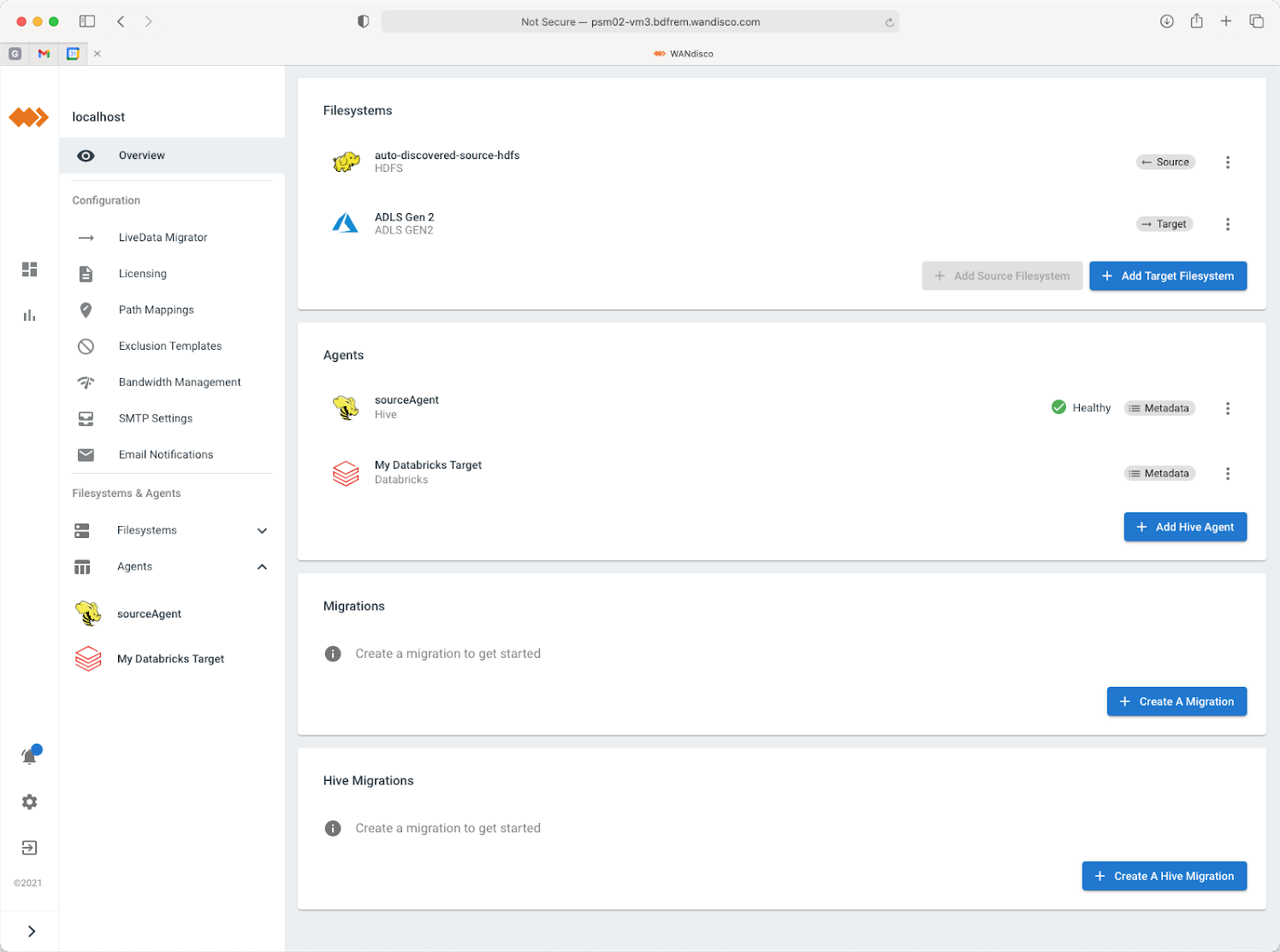
Step 1 - Define your targets
Configure LiveData Migrator to have a data migration target available for your chosen cloud storage and for Databricks. Choose to convert content to the Delta Lake format when you create your Databricks metadata target.

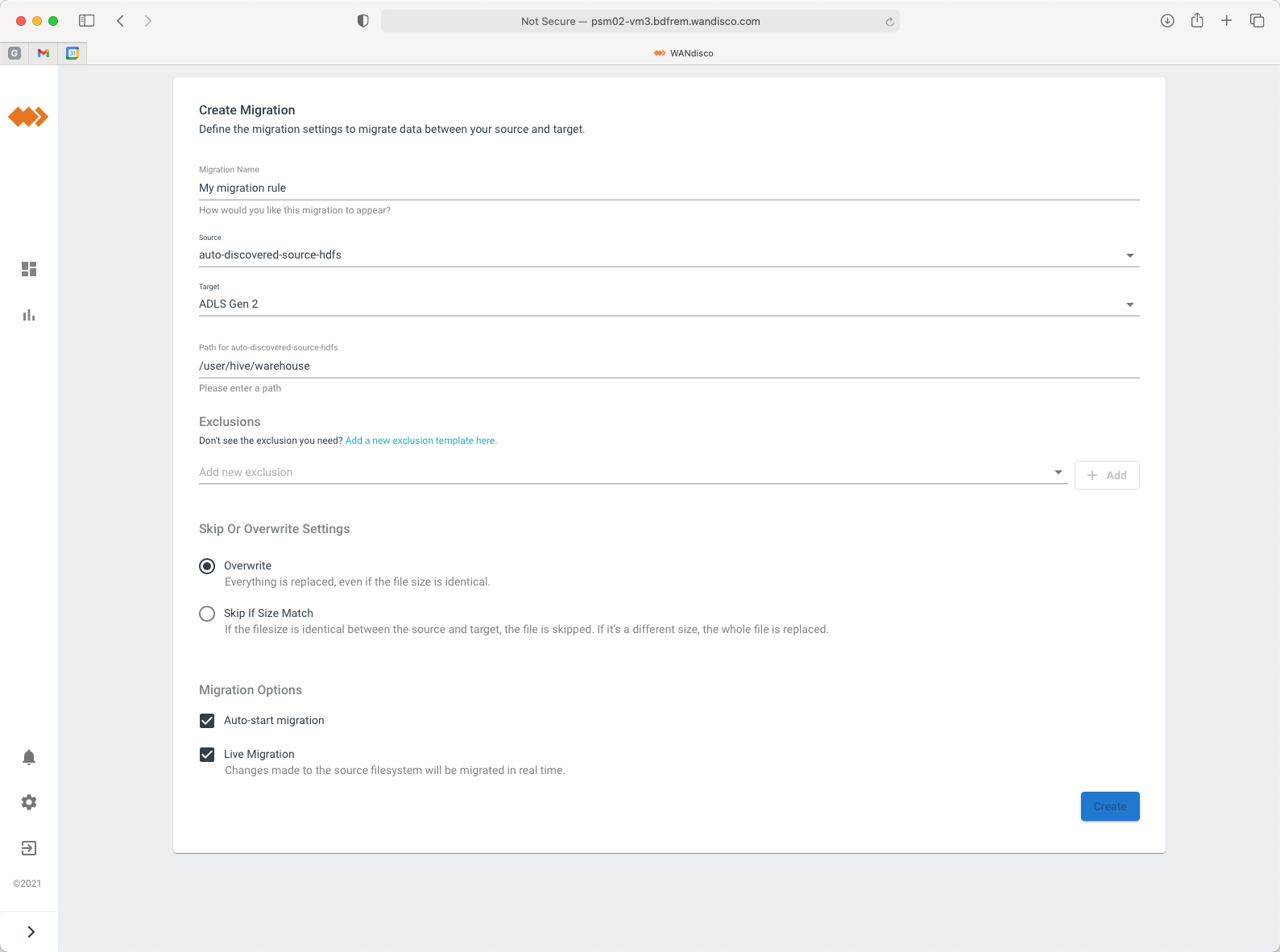
Step 2 - Define your data migration rule
Choose the data you want to migrate by defining a migration rule.
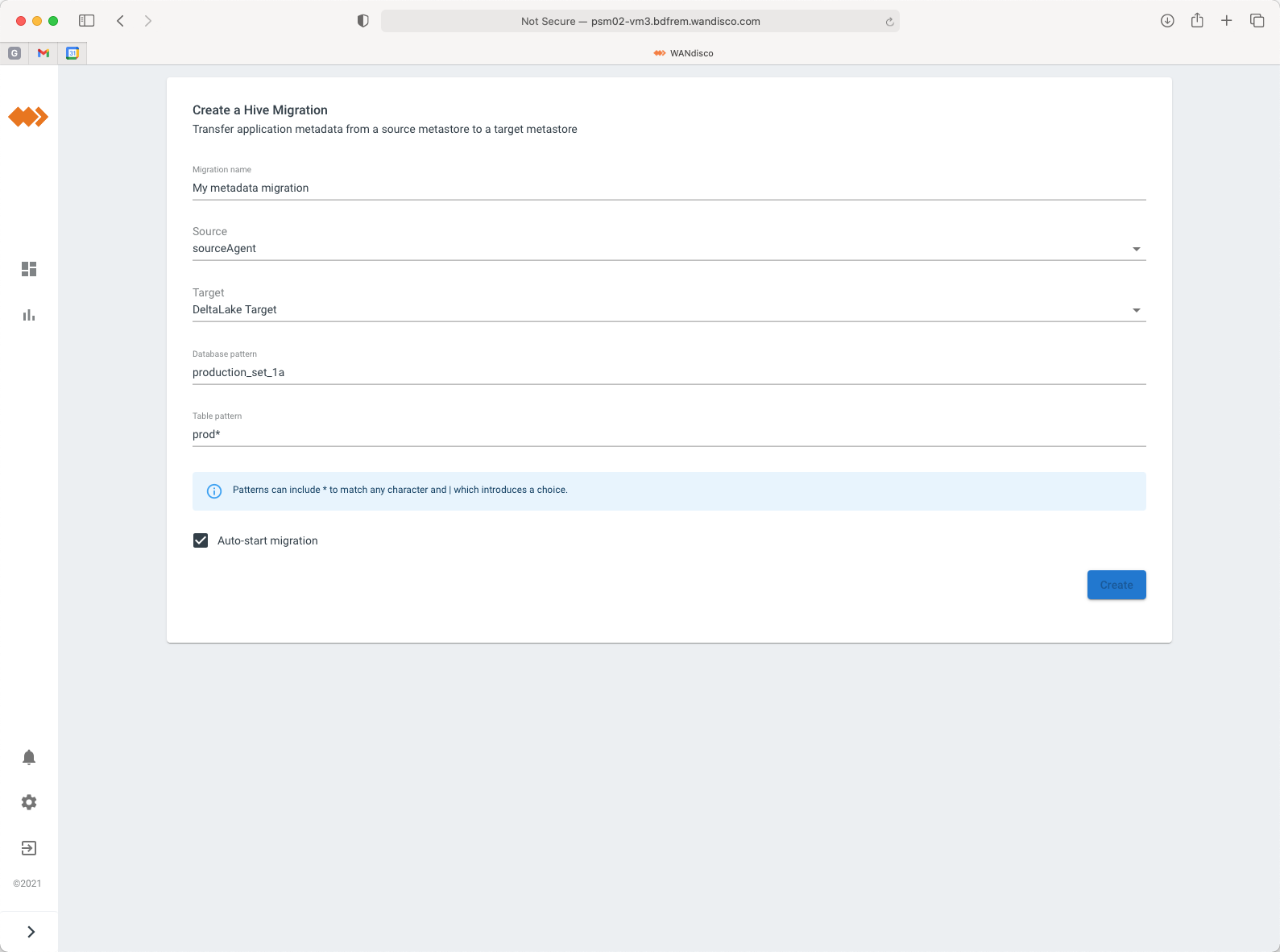
Step 3 - Define your metadata migration
Choose the Hive databases and tables that you want to migrate.
The outcome
For the first time, organizations that want to migrate on-premises Hadoop and Spark content from Hive to Databricks can do so at scale, for Live data, automatically, and selectively without any disruption to their existing systems. This means that cloud migration and modernization are within the scope of constrained teams, without risk, and without imposing a big-bang cutover. Workloads and data that have been locked-up on-premises can now be used immediately in the cloud, using the modern data analytics platform offered by Databricks.
 Paul Scott-Murphy
Paul Scott-Murphy
Chief Technology Officer, WANdisco
Paul has overall responsibility for WANdisco’s product strategy, including the delivery of product to market and its success. This includes directing the product management team, product strategy, requirements definitions, feature management and prioritisation, roadmaps, coordination of product releases with customer and partner requirements and testing. Previously Regional Chief Technology Officer for TIBCO Software in Asia Pacific and Japan. Paul has a Bachelor of Science with first class honours and a Bachelor of Engineering with first class honours from the University of Western Australia.
