
Understanding Value: Moving Hadoop to the Cloud
By Patrick Connolly & Jack Delorey
Dec 10, 2020
Simply moving data from one place to another is fairly straightforward - so at first blush one might assume that simply copying or embarking on a DIY project might be an easy path to achieve the promised land of a Cloud Data Lake. But let’s ask ourselves some questions as we size up this challenge.
Are we talking about a “lift and shift”?
Hopefully not. The value of such an approach would seem to be desirable, but in practice, greater value is within reach by thinking ahead - what if we could simultaneously move the data from Hadoop to multiple targets? Then we’re not simply moving the problem from on-premise to the cloud - but enabling better insights and operations (or as I like to say, “Supercharging” that data for greater insights).
What if the data is changing?
At the simplest level simply moving the data is usually predicated on the need to completely take it off line. Shut it down. Hit the brakes. If the data’s changing, you have to hit the pause button on your business. Got live, actively changing data? That’s simply not a realistic option for today’s “Always On” economy.
What happens if we goof something up on the way?
In prior blogs, we’ve discussed the concept of “Data Gravity” - the notion that data exerts influence on a universe of diverse applications. So, what’s the ripple effect on your business if you don’t get it right the first time, all the time? How can you be 100% certain you’re not going to miss a critical dependency? In our experience, DIY projects take weeks or even months to build and based upon everything we’re discussing here, typically fail. Finally, you must choose an option that is secure and governed - the risks associated with a misstep here are enormous.
Can you afford an outage?
Whether a planned or unplanned outage - what’s the price tag on the ability to access the data? If we’re talking about live data, there is literally no option for shutting the data down intentionally or otherwise.
Where’s the Business Value?
It’s commonplace to discuss Value Engineering and Return on Investment (ROI). I would assert that ROI is interesting but focuses simply on the financial value of a project: ROI is the financial value less project cost divided by the project cost as a percentage. Value Engineering is interesting as it also focuses on function - what’s accomplished and what is the resulting increase in value. With that in mind, let’s focus on some basic levers that are worthy of consideration for our Hadoop to cloud migration journey:
IT Engineering and Labor Savings
How much work can we save? Think about the types of roles that will be involved - developers, engineers, testing and QA resources. As well, we’re going to need project management. Beyond that one must also consider the implications to the end users both in requirements definition and time away from their “day jobs”. Also consider how you’re going to deal with change tracking of petabytes of data and any ongoing changes. Let’s assume a medium-large company - around $1B in revenue. Conservatively we’re talking about 4 full-time resources in our example that will need to work on any migration use cases.
Ongoing Support
This is the second facet of our IT labor variable. Resources will be needed (perhaps 24x7) for support calls, troubleshooting, implementing bug fixes/updates as structures inevitably change. Also think about the ecosystem of technology - what happens if you get a new patch from your Hadoop distribution vendor? Lastly, consider the enhancement requests that are all but inevitable. Here we’ll say 2 resources.
Data Science/Analytics Impact of Disruption
There’s going to be an impact on the consumption side of our equation - consider the Data Scientists, executives, analysts and more. What’s the price tag for the disruption? What’s the cost of troubleshooting flawed data that’s literally untraceable unless you choose the right solution? Here we’ll say between fractions of Data Scientists’ time and the others we’ll have around 2 full resources needed.
Revenue Impacts
What’s the value associated with faster time to market/time to value? If it’s done quickly, effectively and without interruption you could see months of time save to add revenue-producing applications/analytics - with potentially higher ROI for each project. Also consider the competitive advantage and opportunity to capture additional market share. This one’s tricky to calculate. Let’s say for a $1B company we can impact 1% of revenue - that’s $10 million.
Cost Reduction
Now we get to the typical reason we start noodling on moving to the cloud - saving costs. Subscription and license fees, ongoing maintenance and support, as well as the head count needed to operate these systems. Let’s assume $100k for fees, $50k for support and administrative costs - $150k.
Value Summary
So, what does that look like? In our conservative example, we’re talking about a net financial value north of $11 million. In practice I would predict higher costs and a greater revenue opportunity, but it paints a clear picture - these are mission critical technologies. The cost of delaying, getting it wrong and the time lost is potentially far higher.
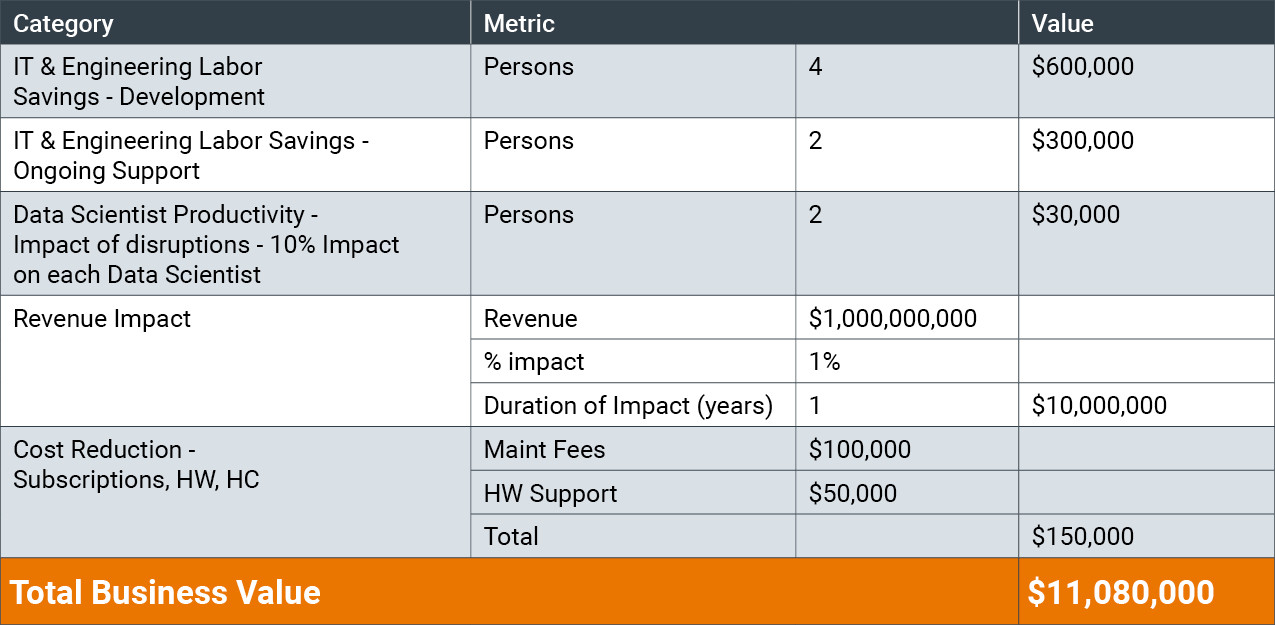
If we return again to the thinking around Value Engineering, we have to look at the functions gained. If we can move and replicate live value to the cloud, we gain far greater accessibility, agility, productivity, and reliability. We get more people and partners insight to take the right actions.
Future Implications
My strongest advice for your efforts would be this: Don’t delay. Each day you put off these migrations increases the size and magnitude of the problems we’ve discussed. Data Gravity doesn’t slow down and the needs of your business demand timely insight. What if there was a solution that is ready, that automates migrations from start to finish? One that can handle actively changing data - even in production that ensures consistency on an ongoing basis. That can send live, actively changing data to multiple targets. That solution is here - that solution is WANdisco’s LiveData Platform.
