
Migrating On-Premises Hadoop Environments to the Cloud
By Tony Velcich
May 14, 2020
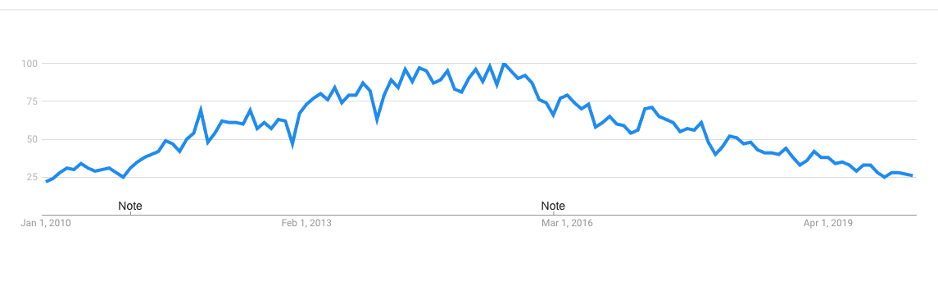
Since January 2010 we have seen Hadoop become an essential part of the data management landscape that most organizations used when building out their data lake infrastructure.
This was particularly true during the first half of the decade, when we saw the top-3 Hadoop distribution vendors (Cloudera, Hortonworks and MapR) grow exponentially. The last few years have been a different story, resulting in the consolidation of Cloudera and Hortonworks, and with HPEs acquisition of struggling MapR.
This rise and fall can be seen using Google Trends to visualize the interest of Hadoop as a search term from January 2010 to April 2020, and depicted in the diagram below:
Hadoop interest over time:
MapR interest over time:
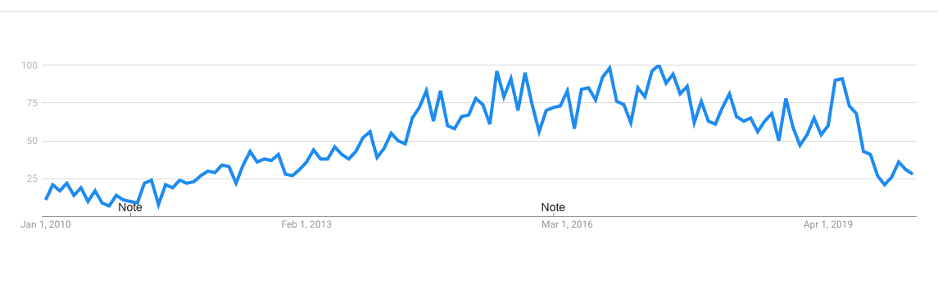
Interestingly searches for MapR dropped significantly right after HPE announced the acquisition. Other than the initial news directly following the announcement there has been little information about MapR causing a lot of uncertainty in the industry.
While Hadoop offered a cost-effective way to store petabytes of data across a distributed environment, it introduced a lot of complexities in order to manage the on-premises environments. The systems required specialized IT skills and the on-premises environments lacked the flexibility to easily scale the systems up and down as usage demands changed.
Growth of Cloud Analytic Offerings
The management complexity and flexibility challenges associated with on-premises Hadoop environments are much more optimally addressed in the cloud. Not only do cloud object stores provide enhanced scalability, elasticity, and manageability at lower costs, they also offer easier integration with other services offered by the Cloud Service Providers (CSPs). Functionality provided by cloud object stores exceeds that which is natively provided by HDFS, and the CSPs own Hadoop offerings such as Amazon EMR and Azure HDInsight take advantage of the same stored data.
Hadoop is not just a single product; it is a collection of different technologies. While batch processing use cases initially associated with MapReduce have been shrinking, other Hadoop components have been growing dramatically. For example, Apache Spark extends the MapReduce model to enable much higher performance for batch operations, as well as interactive queries and streaming.
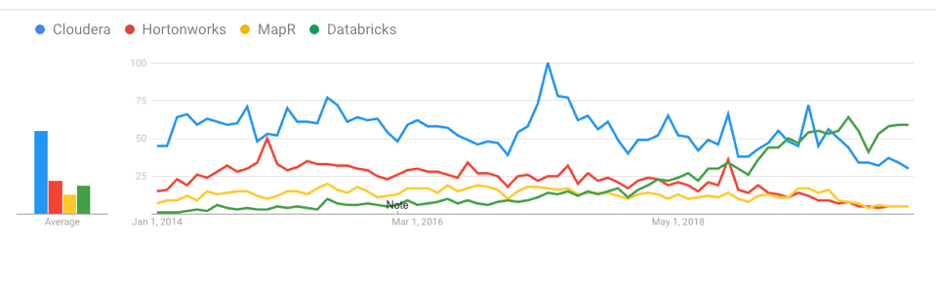
The interest in and growth of Spark can also be witnessed in the following Google Trends diagram, which shows Databricks, a cloud-based Spark Analytics provider founded by the original creators of Apache Spark, surpassing all three traditional Hadoop vendor searches during the past year.
Cloudera, Hortonworks, MapR and Databricks interest over time:
Migrating Hadoop to the Cloud:
Responding to the growing interest in cloud-based solutions, Cloudera and MapR responded with cloud offerings. However, to get there they typically promote a “lift and shift” approach to cloud migration and leverage open-source tools such as DistCp (distributed copy) to perform the migration.
DistCp was designed for inter/intra-cluster copying, and not large-scale data migrations. DistCp is essentially script-driven, operates in batch mode and doesn’t guarantee data consistency if data is actively changing during migration. Therefore, production clusters need to be taken offline during migration, which introduces significant business disruption.
In promoting a “Lift and shift” model, the legacy Hadoop vendors are trying to “lock-in” their existing customers by simply moving their on-premises Hadoop implementations to the cloud without taking advantage new capabilities offered by the CSPs or other cloud analytics providers such as Databricks. Given the uncertainty with the legacy Hadoop offerings do customers really want to lock themselves in further?
Interestingly, on their website MapR talks about avoiding lock-in. They encourage hybrid or multi-cloud strategies so as to avoid public cloud vendor lock-in and promote the use of their global replication capability to copy changes across cloud environments. However, this capability is tightly coupled with a need for low-latency networking and only works from one MapR deployment to another, so it is still locking users into a MapR only solution.
How can organizations migrate petabytes of data from their on-premises Hadoop environments to the cloud, and do so without causing business disruption? Furthermore, how can they set up a modern data architecture that enables them to take advantage of the latest cloud analytics capabilities and provide flexibility without forcing vendor lock-in?
WANdisco Minimizes Risk and Provides True Flexibility:
WANdisco’s LiveData approach enables critical data to be continuously available in any environment, in every location, and at any scale – even when data is actively changing. WANdisco provides the ideal solutions for cloud data migration and enabling hybrid cloud and multi-cloud environments.
WANdisco LiveMigrator automates Hadoop to cloud migration at scale with no application downtime and no risk of data loss, even when data sets are under active change. Because users can continue to use the production environment during migration, organizations can enhance the new environments to leverage advanced cloud analytics capabilities and not just perform a lift and shift of the old environment. As changes occur anywhere in the source system, LiveMigrator ensures 100% data consistency in the target system.
With WANdisco in place, the WANdisco Fusion platform enables organizations to transition to a hybrid cloud architecture, where both the on-premises environment and new cloud environment can be used in parallel. The cloud environment can be enabled for new advanced data science and machine learning algorithms, while the on-premises environment can continue to be used for existing workloads as needed.
As organizations move towards more multi-cloud environments, WANdisco’s patented technology keeps data consistent across multiple data centers no matter where they are in the world. It gives organizations the ability to better support edge computing requirements where computation and data storage are brought closer to the location where it is needed
WANdisco provides ultimate flexibility and enables organizations to handle the uncertainty of quickly changing data requirements, vendors and landscape. It enables organizations to modernize their data infrastructure and do so without causing business disruption. To find out more please visit us a wandisco.com.
About the author

Tony Velcich, Sr. Director of Product Marketing, WANdisco
Tony is an accomplished product management and marketing leader with over 25 years of experience in the software industry. Tony is currently responsible for product marketing at WANdisco, helping to drive go-to-market strategy, content and activities. Tony has a strong background in data management having worked at leading database companies including Oracle, Informix and TimesTen where he led strategy for areas such as big data analytics for the telecommunications industry, sales force automation, as well as sales and customer experience analytics.
